스포츠 AI 예측 모델을 위한 데이터 학습용 CSV 구성 가이드
페이지 정보

본문

AI로 스포츠 경기를 예측하는 시대에 가장 중요한 출발점은 바로 정형화된 CSV 데이터셋입니다. 축구, 야구, 농구 등 어떤 종목이든 경기 데이터를 AI가 학습할 수 있는 구조로 가공해야 하며, 이때 필요한 것이 바로 스포츠 AI 예측 모델을 위한 데이터 학습용 CSV 구성 가이드입니다.
이 글에서는 종목별 공통 필드부터 특화된 피처 설계, 전처리 및 피처 엔지니어링, 데이터 분할과 모델 적용 방법까지 모든 과정을 체계적으로 안내합니다. 특히 Scikit-learn, XGBoost, TensorFlow 등 주요 머신러닝 프레임워크에 맞춘 CSV 설계 노하우를 담아 초급자부터 실전 개발자까지 실용적으로 활용할 수 있습니다.
???? 데이터 학습용 CSV란 무엇인가?
CSV(Comma Separated Values)는 가장 범용적인 데이터 저장 포맷 중 하나로, 각 행은 하나의 경기 기록, 각 열은 하나의 변수(피처)를 의미합니다. 이는 AI 모델이 구조화된 형태로 이해하고 학습할 수 있도록 하는 기반이 되며, 경기에 영향을 주는 요소—예: 팀의 최근 성적, 배당 정보, 경기 장소, 시간대—를 모두 포함할 수 있어 예측 모델의 성능 향상에 결정적입니다.
스포츠 AI 예측 모델을 위한 데이터 학습용 CSV 구성 가이드는 이런 CSV의 구조와 피처 설계, 그리고 전처리 방식까지 포함한 토털 설계 지침서입니다. 실제로 AI가 승패, 득점, 득실차, ROI를 얼마나 정확하게 예측할 수 있는지는 이 CSV의 품질에 달려 있습니다.
⚙️ 1. 기본 구조: 공통 필드 설계 (경기 기반)
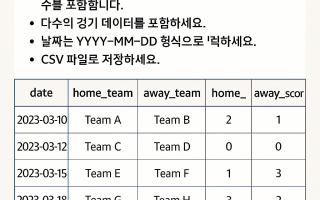
스포츠 종목은 다양하지만, 경기 단위 데이터를 기준으로 공통 필드를 먼저 구성해야 향후 병합·분석·모델링이 수월합니다. 아래는 경기 기반 CSV에서 필수로 포함해야 할 공통 필드 예시입니다:
필드명 설명
match_id 경기 고유 ID
date 경기 일자
league 리그 또는 대회명
home_team / away_team 팀명
home_score / away_score 실제 경기 점수
home_odds / draw_odds / away_odds 배당 정보
home_win 홈팀 승 여부 (1/0)
home_last5_win / away_last5_win 최근 5경기 성적
home_goal_avg / away_goal_avg 평균 득점
이 필드 구조는 모든 종목에 적용 가능하며, 이후 종목별 피처를 추가하면 됩니다. 특히 배당 정보는 AI ROI 모델이나 전략 시뮬레이션에 필수적입니다.
2. 종목별 특화 피처 추가
스포츠마다 승패 결정 요인이 다르기 때문에, 공통 필드 외에 종목별 특화 피처를 반드시 고려해야 합니다.
축구
점유율(possession_avg)
슈팅 수 (shots, shots_on_target)
코너킥 수 (corners)
포메이션 정보 (formation)
야구
선발투수 평균자책점(pitcher_era)
팀 타율, 홈런 수
불펜 ERA, 구장 효과(park_factor)
농구
평균 득/실점(points_avg, opp_points_avg)
리바운드 수, 턴오버 수, 자유투 성공률
경기 페이스(pace), 홈 승률
스타 선수 출전 여부(star_player, 0/1)
이처럼 스포츠 AI 예측 모델을 위한 데이터 학습용 CSV 구성 가이드는 종목 특성을 반영한 정교한 피처 구성으로 AI 모델 정확도를 극대화할 수 있도록 합니다.
3. 타겟 레이블(Label) 설계 방식
모델의 목표에 따라 예측해야 할 타겟 값(Label)은 달라집니다.
이진 분류: 홈팀 승리 여부 예측 (1/0)
다중 분류: 홈승(1), 무승부(2), 원정승(0)
회귀 모델: 득점 차(home_score - away_score)
수익률 모델: ROI 기대값 예측
실제로는 아래와 같이 apply()를 사용해 다중 클래스 레이블을 생성할 수 있습니다:
python
복사
편집
df['label'] = df.apply(lambda x: 1 if x['home_score'] > x['away_score'] else (2 if x['home_score']==x['away_score'] else 0), axis=1)
정확한 라벨링은 예측 모델의 신뢰도를 높이며, 스포츠 AI 예측 모델을 위한 데이터 학습용 CSV 구성 가이드의 핵심 지점 중 하나입니다.
4. 데이터 수집 소스 확보
공식 API: API-Football, Sportradar, MLB/NBA Stats API 등
오픈 CSV: Kaggle, sports-statistics.com, github 공개 저장소
웹 크롤링: ESPN, Sofascore, Flashscore 등 HTML 구조 활용
Google Sheets 연동: 수작업 입력 → CSV 추출 자동화
데이터 신뢰도와 최신성을 고려해 API 기반 + 보조 크롤링 조합이 이상적입니다.
5. 기본 전처리 (Cleaning)
날짜 → datetime 형 변환
리그, 팀 이름 정규화 (lowercase, 공백/기호 제거 등)
승/무/패 → 숫자 인코딩 (home_win: 1/0, label: 0/1/2 등)
배당 → 로그 변환, 확률 변환 (1 / odds)
결측치 처리: 평균, 중앙값, unknown 채우기
예시:
python
복사
편집
df['date'] = pd.to_datetime(df['date'])
df['home_odds_log'] = np.log(df['home_odds'])
df['home_win_prob'] = 1 / df['home_odds']
6. 데이터 정제 및 이상치 처리
극단값 제거: 득점 15점 이상, 배당 1.01 등
저신뢰 경기 필터링: 일부 API는 전반/후반 득점 없이 종료된 경기 존재
결측 필드별 전략:
formation → unknown
pitcher_era → 평균
star_player → 0
7. CSV 정렬 및 구조화
match_id, date, league 등 고정 컬럼 먼저 배치
target(label) 컬럼은 마지막 또는 분리 보관
종목별 suffix 부여 (예: shots_on_target_soccer)
8. 샘플 CSV 예시 설계 (축구)
csv
복사
편집
match_id,date,league,home_team,away_team,home_score,away_score,home_odds,draw_odds,away_odds,label,shots,possession_avg
20230610,EPL,Man City,Chelsea,2,1,1.55,3.2,5.1,1,17,61.2
정규화된 팀명, 날짜 형식, 배당 값 필수 확인.
9. 야구 예시 필드 확장
csv
복사
편집
pitcher_era,team_avg,home_runs,bullpen_era,park_factor_home
3.25,0.261,4,3.75,0.92
선발/불펜 성능 + 구장 지수 조합이 중요
종종 회차 단위(row) 확장도 필요 (예: 1회~9회 데이터 개별화)
10. 데이터셋 분할
python
복사
편집
from sklearn.model_selection import train_test_split
X = df.drop(['label','match_id','date'], axis=1)
y = df['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
시계열 예측 시 shuffle=False
시즌 구간별 분할(2022~2023 훈련, 2024 테스트 등)
11. 모델링 및 검증
분류 모델: XGBoost, LightGBM, RandomForest
회귀 모델: 득점차, ROI 예측
평가 지표: F1 Score, Precision, Recall, RMSE, MAE
12. Google Sheets ↔ GitHub 자동화 연동
Zapier + Google API → Git 커밋
GitHub Actions: 모델 학습 자동화
.ipynb + Streamlit → 웹 대시보드 자동화
13. 종목별 피처 설계 전략
종목 특화 피처
축구 슈팅, 점유율, 포메이션
야구 선발 ERA, 불펜, 홈런
농구 pace, rebound, turnover, ft_pct
모든 피처는 종목의 승패 결정 메커니즘에 기반해 설계되어야 함.
14. 데이터 품질 관리 기준
최소 1,000경기 이상
클래스 불균형 ≤ 3:1
필드별 결측치 5% 이하
정확한 라벨 정의 (label, home_win 구분 필요)
15. Feature Engineering (파생 변수 생성)
득실차: goal_diff = home_score - away_score
최근 승률 차이: home_last5_win - away_last5_win
배당 비율: home_odds / away_odds
ROI 예측을 위한 log(odds) * win_prob 계산
16. 검증 전략 설계
train/val/test = 70/15/15 분할
season-based split: 과거 시즌 → 미래 시즌 예측
league-based split: KBO vs MLB, EPL vs LaLiga 구분
17. 버전 관리 및 저장 경로
파일명: data/soccer_ai_2024.csv, ..._baseball.csv
버전 기록: v1.0, v1.1_beta 등
Git 커밋 시점에 모델 코드 및 CSV 함께 저장
18. 자동 전처리 스크립트
python
복사
편집
df['date'] = pd.to_datetime(df['date'])
df.dropna(subset=['home_odds','away_odds'], inplace=True)
df['goal_diff'] = df['home_score'] - df['away_score']
df['home_odds_log'] = np.log(df['home_odds'])
로그 변환, 결측 제거, 파생 피처 생성 포함
train_test_split()까지 포함한 전체 파이프라인화 권장
19. API 및 오픈데이터 활용 전략
API 활용은 실시간 분석이나 대규모 모델링 시 매우 유용합니다. 예를 들어:
축구: API‑Football, Opta, Sofascore
야구: MLB API, Statcast
농구: NBA Stats API, Basketball-Reference
이 외에도 Kaggle, sports-statistics.com, wired.com 등에서 공개 CSV를 확보할 수 있습니다. 데이터 자동화를 위해 Python 크론 스케줄러나 Zapier도 함께 연동하면 정기 업데이트 시스템이 완성됩니다.
20. FAQ 요약
Q: CSV에 배당 정보 꼭 필요할까요?
A: ROI나 전략 분석에는 필수이며, 승패 예측 모델에는 선택적입니다.
Q: 무승부 처리 방식은?
A: 다중 분류 시 별도 클래스, 이진 분류 시 제거하거나 0으로 통합 가능합니다.
Q: 종목별 대응 전략은?
A: 각 종목의 특성(예: 야구 ERA, 농구 pace)을 반영한 피처 설계가 필요합니다.
Q: 데이터 정확도는 어떻게 확보하나요?
A: API 기반 데이터를 우선 사용하고, 수작업 입력 시 교차 검증 실시하세요.
✅ 최종 요약
스포츠 AI 예측 모델을 위한 데이터 학습용 CSV 구성 가이드는 단순한 파일 구조를 넘어, AI 예측 모델의 성능을 좌우하는 설계 매뉴얼입니다. 다음 요소를 반드시 고려하세요:
✅ 스포츠 AI 예측 모델을 위한 CSV 설계 핵심 절차
경기 기반 공통 필드 설계
모든 종목에 적용 가능한 기본 피처 정의
예: match_id, date, league, home_team, away_team, score, odds 등
종목별 특화 피처 반영
축구: 슈팅 수, 점유율, 포메이션
야구: 투수 ERA, 홈런, 불펜 지표
농구: 페이스, 리바운드, 턴오버 등
데이터 전처리 및 정제
날짜 포맷 통일
결측치 처리
배당 로그변환 및 정규화
이상치 제거 및 스케일링
레이블링 전략
이진 분류(승/패), 다중 분류(승/무/패), 회귀(득점 차), ROI 예측 등
목적에 맞는 label 컬럼 생성 로직 구성
피처 엔지니어링 및 검증 구조
득실차, 최근 승률 차, 배당 비율 등 파생 변수 생성
모델 학습을 위한 train/test 분할 전략 수립
자동화 및 버전 관리 시스템
Google Sheets ↔ GitHub 연동
Jupyter Notebook 기반 전처리 자동화
CSV 버전 관리 및 스케줄링
이 가이드를 기반으로 스포츠 데이터 분석의 전체 파이프라인을 체계화할 수 있으며, 실제 예측 모델의 성능과 신뢰도도 크게 향상시킬 수 있습니다.
#스포츠AI예측 #경기데이터CSV #배당분석 #축구데이터분석 #야구AI모델 #농구예측모델 #피처엔지니어링 #머신러닝스포츠 #데이터전처리 #스포츠모델학습
이 글에서는 종목별 공통 필드부터 특화된 피처 설계, 전처리 및 피처 엔지니어링, 데이터 분할과 모델 적용 방법까지 모든 과정을 체계적으로 안내합니다. 특히 Scikit-learn, XGBoost, TensorFlow 등 주요 머신러닝 프레임워크에 맞춘 CSV 설계 노하우를 담아 초급자부터 실전 개발자까지 실용적으로 활용할 수 있습니다.
???? 데이터 학습용 CSV란 무엇인가?
CSV(Comma Separated Values)는 가장 범용적인 데이터 저장 포맷 중 하나로, 각 행은 하나의 경기 기록, 각 열은 하나의 변수(피처)를 의미합니다. 이는 AI 모델이 구조화된 형태로 이해하고 학습할 수 있도록 하는 기반이 되며, 경기에 영향을 주는 요소—예: 팀의 최근 성적, 배당 정보, 경기 장소, 시간대—를 모두 포함할 수 있어 예측 모델의 성능 향상에 결정적입니다.
스포츠 AI 예측 모델을 위한 데이터 학습용 CSV 구성 가이드는 이런 CSV의 구조와 피처 설계, 그리고 전처리 방식까지 포함한 토털 설계 지침서입니다. 실제로 AI가 승패, 득점, 득실차, ROI를 얼마나 정확하게 예측할 수 있는지는 이 CSV의 품질에 달려 있습니다.
⚙️ 1. 기본 구조: 공통 필드 설계 (경기 기반)
스포츠 종목은 다양하지만, 경기 단위 데이터를 기준으로 공통 필드를 먼저 구성해야 향후 병합·분석·모델링이 수월합니다. 아래는 경기 기반 CSV에서 필수로 포함해야 할 공통 필드 예시입니다:
필드명 설명
match_id 경기 고유 ID
date 경기 일자
league 리그 또는 대회명
home_team / away_team 팀명
home_score / away_score 실제 경기 점수
home_odds / draw_odds / away_odds 배당 정보
home_win 홈팀 승 여부 (1/0)
home_last5_win / away_last5_win 최근 5경기 성적
home_goal_avg / away_goal_avg 평균 득점
이 필드 구조는 모든 종목에 적용 가능하며, 이후 종목별 피처를 추가하면 됩니다. 특히 배당 정보는 AI ROI 모델이나 전략 시뮬레이션에 필수적입니다.
2. 종목별 특화 피처 추가
스포츠마다 승패 결정 요인이 다르기 때문에, 공통 필드 외에 종목별 특화 피처를 반드시 고려해야 합니다.
축구
점유율(possession_avg)
슈팅 수 (shots, shots_on_target)
코너킥 수 (corners)
포메이션 정보 (formation)
야구
선발투수 평균자책점(pitcher_era)
팀 타율, 홈런 수
불펜 ERA, 구장 효과(park_factor)
농구
평균 득/실점(points_avg, opp_points_avg)
리바운드 수, 턴오버 수, 자유투 성공률
경기 페이스(pace), 홈 승률
스타 선수 출전 여부(star_player, 0/1)
이처럼 스포츠 AI 예측 모델을 위한 데이터 학습용 CSV 구성 가이드는 종목 특성을 반영한 정교한 피처 구성으로 AI 모델 정확도를 극대화할 수 있도록 합니다.
3. 타겟 레이블(Label) 설계 방식
모델의 목표에 따라 예측해야 할 타겟 값(Label)은 달라집니다.
이진 분류: 홈팀 승리 여부 예측 (1/0)
다중 분류: 홈승(1), 무승부(2), 원정승(0)
회귀 모델: 득점 차(home_score - away_score)
수익률 모델: ROI 기대값 예측
실제로는 아래와 같이 apply()를 사용해 다중 클래스 레이블을 생성할 수 있습니다:
python
복사
편집
df['label'] = df.apply(lambda x: 1 if x['home_score'] > x['away_score'] else (2 if x['home_score']==x['away_score'] else 0), axis=1)
정확한 라벨링은 예측 모델의 신뢰도를 높이며, 스포츠 AI 예측 모델을 위한 데이터 학습용 CSV 구성 가이드의 핵심 지점 중 하나입니다.
4. 데이터 수집 소스 확보
공식 API: API-Football, Sportradar, MLB/NBA Stats API 등
오픈 CSV: Kaggle, sports-statistics.com, github 공개 저장소
웹 크롤링: ESPN, Sofascore, Flashscore 등 HTML 구조 활용
Google Sheets 연동: 수작업 입력 → CSV 추출 자동화
데이터 신뢰도와 최신성을 고려해 API 기반 + 보조 크롤링 조합이 이상적입니다.
5. 기본 전처리 (Cleaning)
날짜 → datetime 형 변환
리그, 팀 이름 정규화 (lowercase, 공백/기호 제거 등)
승/무/패 → 숫자 인코딩 (home_win: 1/0, label: 0/1/2 등)
배당 → 로그 변환, 확률 변환 (1 / odds)
결측치 처리: 평균, 중앙값, unknown 채우기
예시:
python
복사
편집
df['date'] = pd.to_datetime(df['date'])
df['home_odds_log'] = np.log(df['home_odds'])
df['home_win_prob'] = 1 / df['home_odds']
6. 데이터 정제 및 이상치 처리
극단값 제거: 득점 15점 이상, 배당 1.01 등
저신뢰 경기 필터링: 일부 API는 전반/후반 득점 없이 종료된 경기 존재
결측 필드별 전략:
formation → unknown
pitcher_era → 평균
star_player → 0
7. CSV 정렬 및 구조화
match_id, date, league 등 고정 컬럼 먼저 배치
target(label) 컬럼은 마지막 또는 분리 보관
종목별 suffix 부여 (예: shots_on_target_soccer)
8. 샘플 CSV 예시 설계 (축구)
csv
복사
편집
match_id,date,league,home_team,away_team,home_score,away_score,home_odds,draw_odds,away_odds,label,shots,possession_avg
20230610,EPL,Man City,Chelsea,2,1,1.55,3.2,5.1,1,17,61.2
정규화된 팀명, 날짜 형식, 배당 값 필수 확인.
9. 야구 예시 필드 확장
csv
복사
편집
pitcher_era,team_avg,home_runs,bullpen_era,park_factor_home
3.25,0.261,4,3.75,0.92
선발/불펜 성능 + 구장 지수 조합이 중요
종종 회차 단위(row) 확장도 필요 (예: 1회~9회 데이터 개별화)
10. 데이터셋 분할
python
복사
편집
from sklearn.model_selection import train_test_split
X = df.drop(['label','match_id','date'], axis=1)
y = df['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
시계열 예측 시 shuffle=False
시즌 구간별 분할(2022~2023 훈련, 2024 테스트 등)
11. 모델링 및 검증
분류 모델: XGBoost, LightGBM, RandomForest
회귀 모델: 득점차, ROI 예측
평가 지표: F1 Score, Precision, Recall, RMSE, MAE
12. Google Sheets ↔ GitHub 자동화 연동
Zapier + Google API → Git 커밋
GitHub Actions: 모델 학습 자동화
.ipynb + Streamlit → 웹 대시보드 자동화
13. 종목별 피처 설계 전략
종목 특화 피처
축구 슈팅, 점유율, 포메이션
야구 선발 ERA, 불펜, 홈런
농구 pace, rebound, turnover, ft_pct
모든 피처는 종목의 승패 결정 메커니즘에 기반해 설계되어야 함.
14. 데이터 품질 관리 기준
최소 1,000경기 이상
클래스 불균형 ≤ 3:1
필드별 결측치 5% 이하
정확한 라벨 정의 (label, home_win 구분 필요)
15. Feature Engineering (파생 변수 생성)
득실차: goal_diff = home_score - away_score
최근 승률 차이: home_last5_win - away_last5_win
배당 비율: home_odds / away_odds
ROI 예측을 위한 log(odds) * win_prob 계산
16. 검증 전략 설계
train/val/test = 70/15/15 분할
season-based split: 과거 시즌 → 미래 시즌 예측
league-based split: KBO vs MLB, EPL vs LaLiga 구분
17. 버전 관리 및 저장 경로
파일명: data/soccer_ai_2024.csv, ..._baseball.csv
버전 기록: v1.0, v1.1_beta 등
Git 커밋 시점에 모델 코드 및 CSV 함께 저장
18. 자동 전처리 스크립트
python
복사
편집
df['date'] = pd.to_datetime(df['date'])
df.dropna(subset=['home_odds','away_odds'], inplace=True)
df['goal_diff'] = df['home_score'] - df['away_score']
df['home_odds_log'] = np.log(df['home_odds'])
로그 변환, 결측 제거, 파생 피처 생성 포함
train_test_split()까지 포함한 전체 파이프라인화 권장
19. API 및 오픈데이터 활용 전략
API 활용은 실시간 분석이나 대규모 모델링 시 매우 유용합니다. 예를 들어:
축구: API‑Football, Opta, Sofascore
야구: MLB API, Statcast
농구: NBA Stats API, Basketball-Reference
이 외에도 Kaggle, sports-statistics.com, wired.com 등에서 공개 CSV를 확보할 수 있습니다. 데이터 자동화를 위해 Python 크론 스케줄러나 Zapier도 함께 연동하면 정기 업데이트 시스템이 완성됩니다.
20. FAQ 요약
Q: CSV에 배당 정보 꼭 필요할까요?
A: ROI나 전략 분석에는 필수이며, 승패 예측 모델에는 선택적입니다.
Q: 무승부 처리 방식은?
A: 다중 분류 시 별도 클래스, 이진 분류 시 제거하거나 0으로 통합 가능합니다.
Q: 종목별 대응 전략은?
A: 각 종목의 특성(예: 야구 ERA, 농구 pace)을 반영한 피처 설계가 필요합니다.
Q: 데이터 정확도는 어떻게 확보하나요?
A: API 기반 데이터를 우선 사용하고, 수작업 입력 시 교차 검증 실시하세요.
✅ 최종 요약
스포츠 AI 예측 모델을 위한 데이터 학습용 CSV 구성 가이드는 단순한 파일 구조를 넘어, AI 예측 모델의 성능을 좌우하는 설계 매뉴얼입니다. 다음 요소를 반드시 고려하세요:
✅ 스포츠 AI 예측 모델을 위한 CSV 설계 핵심 절차
경기 기반 공통 필드 설계
모든 종목에 적용 가능한 기본 피처 정의
예: match_id, date, league, home_team, away_team, score, odds 등
종목별 특화 피처 반영
축구: 슈팅 수, 점유율, 포메이션
야구: 투수 ERA, 홈런, 불펜 지표
농구: 페이스, 리바운드, 턴오버 등
데이터 전처리 및 정제
날짜 포맷 통일
결측치 처리
배당 로그변환 및 정규화
이상치 제거 및 스케일링
레이블링 전략
이진 분류(승/패), 다중 분류(승/무/패), 회귀(득점 차), ROI 예측 등
목적에 맞는 label 컬럼 생성 로직 구성
피처 엔지니어링 및 검증 구조
득실차, 최근 승률 차, 배당 비율 등 파생 변수 생성
모델 학습을 위한 train/test 분할 전략 수립
자동화 및 버전 관리 시스템
Google Sheets ↔ GitHub 연동
Jupyter Notebook 기반 전처리 자동화
CSV 버전 관리 및 스케줄링
이 가이드를 기반으로 스포츠 데이터 분석의 전체 파이프라인을 체계화할 수 있으며, 실제 예측 모델의 성능과 신뢰도도 크게 향상시킬 수 있습니다.
#스포츠AI예측 #경기데이터CSV #배당분석 #축구데이터분석 #야구AI모델 #농구예측모델 #피처엔지니어링 #머신러닝스포츠 #데이터전처리 #스포츠모델학습
- 이전글버튼 클릭 후 반응속도 딜레이가 UX와 사용자 감정에 미치는 영향 25.06.25
- 다음글바카라 다중 회차 통계 자동화 시스템 구축 25.06.20
댓글목록
등록된 댓글이 없습니다.